Azure SQL Database の「仮想ベースの購入モデル」以下のサービスレベルが存在します。
- General Purpose (汎用目的)
- Business Critical (ビジネス不可欠)
- Hyperscale (ハイパースケール)
※ General Purpose (汎用目的) のみ、コンピューティング レベルとして「プロビジョニング済み」もしくは「サーバーレス」を選択可能。
今回は、General Purpose (汎用目的) と Business Critical (ビジネス不可欠) とは異なるアーキテクチャで実装された「Hyperscale (ハイパースケール) 」のアーキテクチャについて、自分の整理も兼ねてまとめてみようと思います。
- Hyperscale サービスレベルとは
- Hyperscale の可用性
- Hyperscale のユースケース
- Hyperscale のアーキテクチャ
- Hyperscale を使用する上での注意点
- まとめ
- 参考URL
Hyperscale サービスレベルとは
「仮想ベースの購入モデル」 のサービスレベルの一つとなり、General Purpose (汎用目的) や Business Critical (ビジネス不可欠) と比較し、以下のようなメリットがあります。
- 最大 100 TB のデータベース サイズ (他のサービスレベルの最大 データベース サイズは 4 TB)
- データベースのサイズに依存しない高速データベースバックアップ機能 (Azure Blob ストレージのファイル スナップショットを使用)
- 高速データベース復元機能 (Azure Blob ストレージのファイル スナップショットによる復元)
Hyperscale の可用性
- 2つ以上の読み取り専用レプリカを持つ Azure SQL Database Hyperscale : 99.99 %
- 1つ以上の読み取り専用レプリカを持つ Azure SQL Database Hyperscale : 99.95 %
- 読み取り専用レプリカがない場合 : 99.9 %
Hyperscale のユースケース
- 4TB 以上のデータベースを移行する必要がある場合
- 既に Azure SQL Database を使用しているが、データベースの最大サイズ (4TG) 制限によって制限されている場合
- RTO(目標復旧時間) 要件が高い場合
- データベースの自動拡張機能を使用したい場合
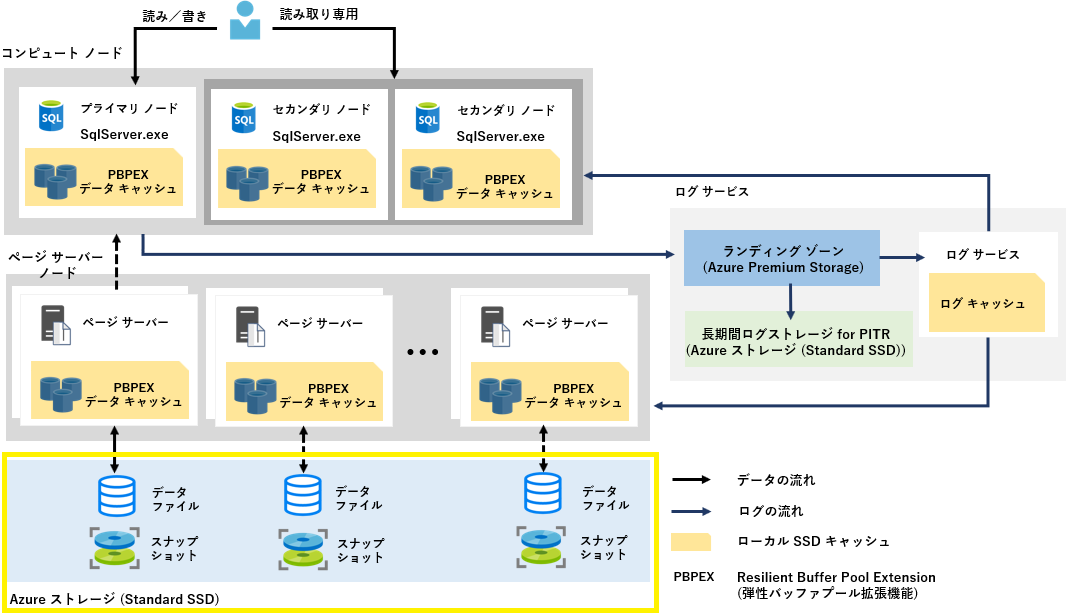
Hyperscale のアーキテクチャ
General Purpose (汎用目的) や Business Critical (ビジネス不可欠) の構成と異なり、コンピュートノード、ページ サーバー ノード、ログ サービス、ストレージのように、クエリ処理エンジン、データを長期的に保存するストレージなどのコンポーネントが疎結合的に組み合わさったアーキテクチャになっています。
各々のコンポーネントについて簡単にまとめてみます。
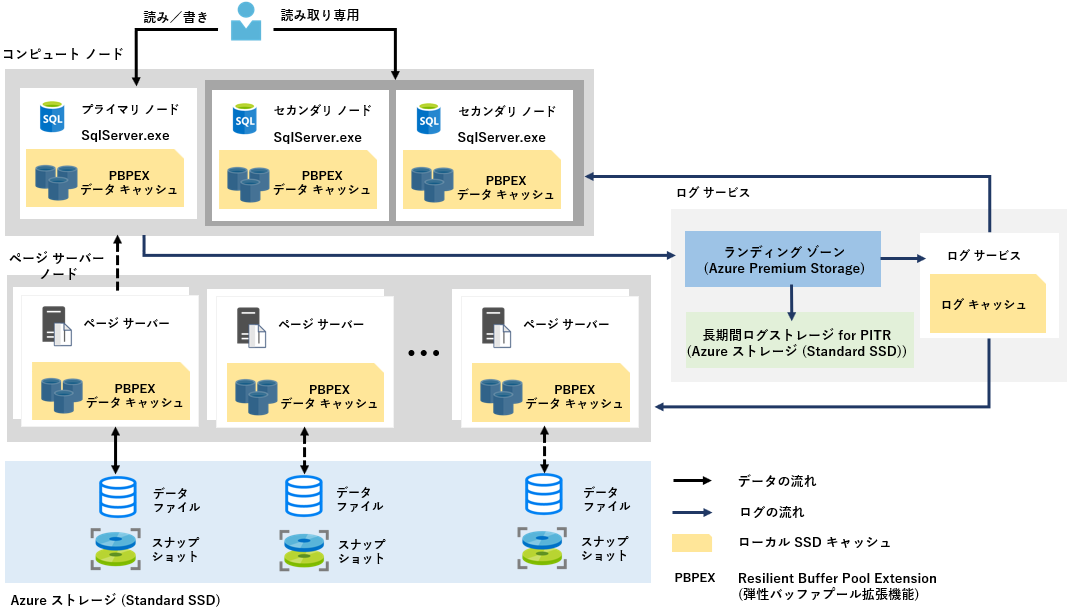
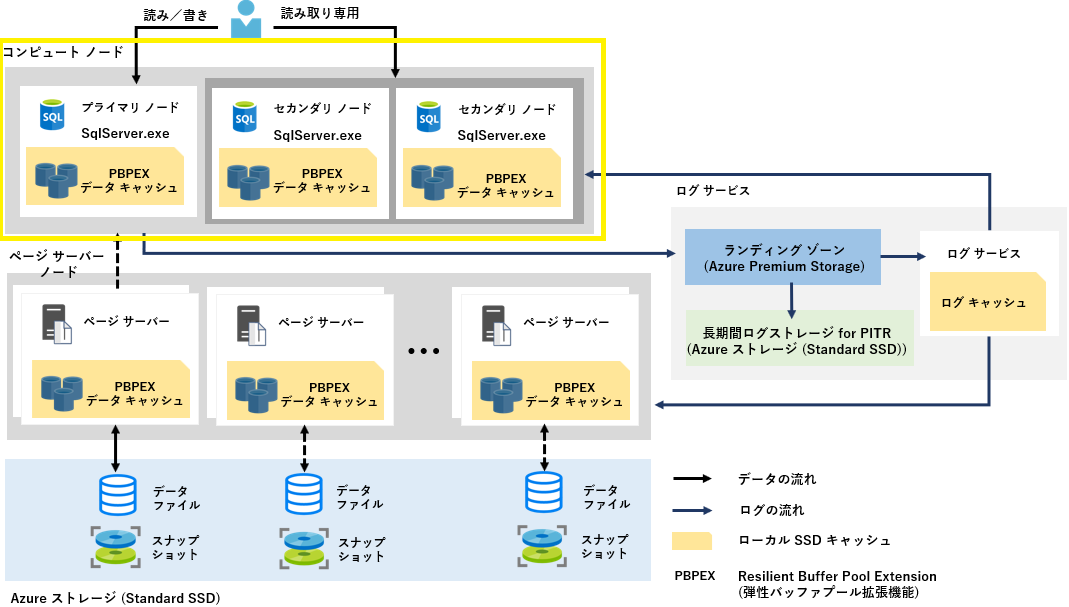
コンピュートノード
SQL Server プロセス (リレーショナル エンジン) が存在し、 クエリの構文解析、クエリの実行、トランザクション管理などの処理が行われるノード。
データ ページをページ サーバー ノードから頻繁にアクセスすることによるネットワーク通信のボトルネックを最小限に抑えるため、コンピューティングノードに PBPEX (Resillient Buffer Pool Extention) という SSDベースのキャッシュを備えており、データページのキャッシュなどは、メモリ および PBPEX 上にキャッシュされる構成になっている。
※ PBPEX は、SQL Server のバッファー プール拡張機能みたいなもの。
コンピュートノードには、「読み/書き」、「読み取り専用」の2種類あり、「読み/書き」ノードは 1つのみ、「読み取り専用」は複数ノードをプロビジョニングすることができる。
[補足]
コンピュート ノード (プライマリ) から「sys.sysfiles」コマンドを実行すると、以下の例では、「data_0」~「data_3」と4つのデータベース物理ファイル(mdf/ndf) で構成されていることが確認できますが、各データベース物理ファイルは、各ページサーバーに紐づいている。

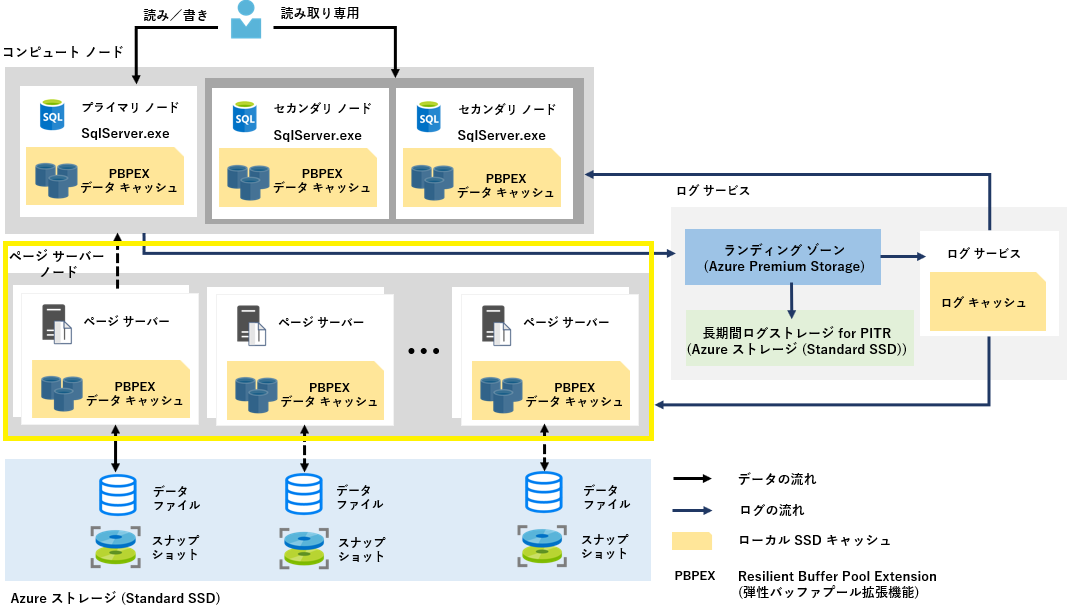
ページ サーバー ノード
スケールアウトされたストレージ エンジン。 各ページ サーバーは、実際に Azure ストレージ (Standard SDD) に配置されたデータベース物理ファイル(mdf/ndf) からのデータページのキャッシュを保持するノード。
コンピュート ノードと同様に、PBPEX (Resillient Buffer Pool Extention) という SSDベースのキャッシュを備えている。
各ページサーバーでは、最大128GB (Azure SQL Database Hyperscale へのサービスレベル変更の場合は 最大 1TB ) のデータがキャッシュされ、各ページ サーバー毎に特定のデータベース物理ファイル (mdf/ndf) が紐づいているため、複数のページ サーバーで同じデータが共有されることはない構成になっている。
また、ページサーバー ノードは、トランザクションでデータが更新されたログレコードをログ サービスから受け取り、キャッシュ (メモリ (PBPEX)) 上のデータページの状態を最新の状態に維持する役割をもっており、非同期により Azure ストレージ (Standard SDD) への反映処理も行われる。
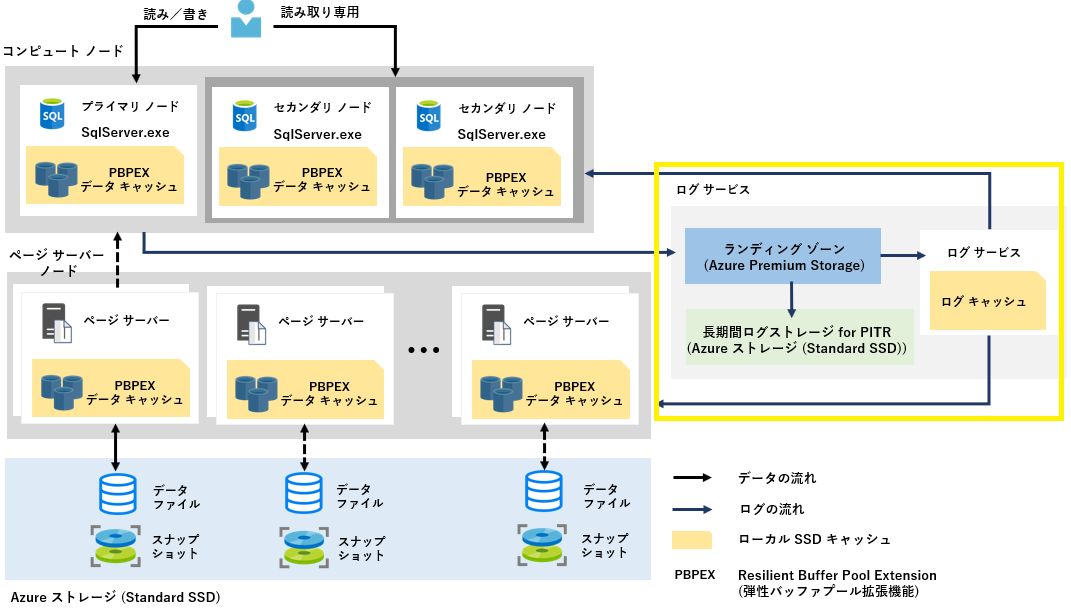
ログ サービス
「読み/書き」(プライマリ) からログ レコードを受け取り、全ての「読み取り専用」コンピュート ノード と 全てのページ サーバーにログ レコードを送付する役割を担っている。
最後に Point in Time Restore (PITR) 用途に使用するため、Azure ストレージ (Standard SDD) へログレコードが保持される。
Azure ストレージ
データベース物理ファイル (mdf/ndf) は Azure ストレージ上に配置されているため、Azure ストレージのファイル スナップショット機能により、ファイルサイズに依存せず、即座にバックアップ/復元 操作を実施することが可能。
Hyperscale を使用する上での注意点
- 別のサービスレベルから Azure SQL Database Hyperscale に変更した場合、もとのサービスレベル (General Purpose (汎用目的), Business Critical (ビジネス不可欠) など) に戻すことができない。
- Hyperscale 以外のデータベースを Hyperscale として復元することはできず、また、Hyperscale のデータベースを別のサービスレベルのデータベースとして復元することはできない。
- 別のサービスレベルで既に データベース サイズが 1TB を超えている場合、Hyperscale に変更することができない。
まとめ
今回は、「Hyperscale (ハイパースケール) 」のアーキテクチャについて、まとめてみました。 General Purpose (汎用目的) と Business Critical (ビジネス不可欠) とは異なるアーキテクチャにより、大規模データベースの構成を実現しており、OLTP (OnLine Transaction Processing) システムで 4 TB 以上のデータベースを扱う必要がある場合の選択肢の一つとして考えることができそうです。
しかしながら、データベースの最大サイズが 4TB 以下であることが確定しており、高い可用性、高いスループットが求められるシステムの場合、IOPSの性能が高い Business Critical (ビジネス不可欠) (SLA : 99.995 (ゾーン冗長)) を使用することを先に検討するほうが良いかと思います。

参考URL