前回、「Microsoft Fabric」の試用版 (60日間) を利用する方法についてまとめてみました。
今回は、「Microsoft Fabric」を利用するメリット (前半) について、まとめてみようと思います。
※ Microsoft Fabric に関するセミナーなどで得た情報や実際に利用したみた経験をベースに、個人的にメリットと思われる点についてまとめています。
Microsoft Fabric メリット (前半)
共通のインターフェースによるデータ分析が可能
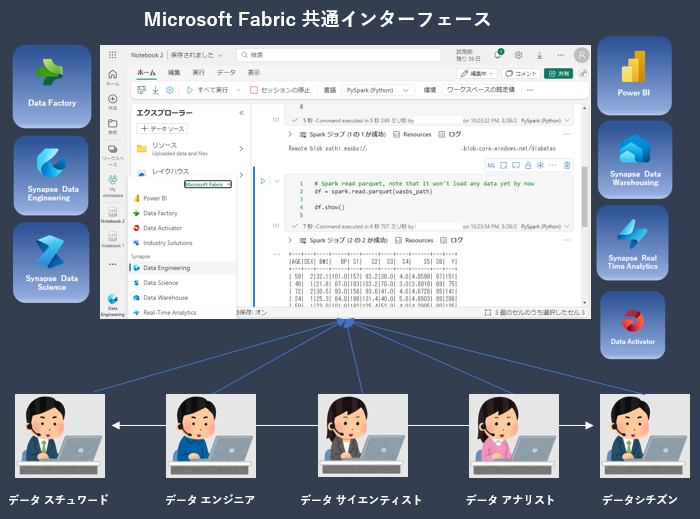
- データ サイエンティスト、データ アナリスト などの異なるロールのエンジニアが Microsoft Fabric 共通のインターフェース上でデータの取得、加工、分析、視覚化を実施することが可能。
- 異なるロールのエンジニア間で効率的にデータのやり取り、データ内容/分析に関する相談などを実施することが可能。
Microsoft Fabric に統合されたワークロードで Microsoft Fabric コンピューティング プールを共有して利用可能
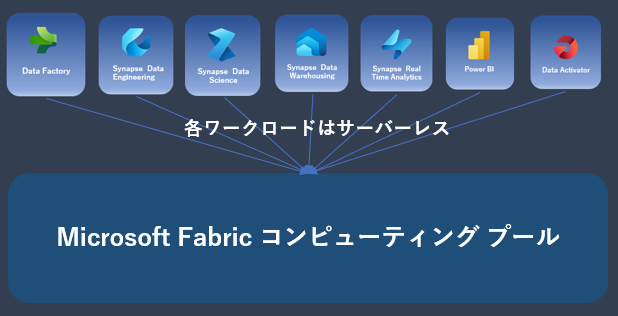
- Microsoft Fabric に統合された各ワークロードはサーバーレスで動作し、動作に必要なリソースは Microsoft Fabric コンピューティング プールから割り当てることが可能。(最小分単位の従量課金 もしくは リソース予約)
- Microsoft Fabric に統合された各ワークロード毎にコンピューティング リソースを購入する必要がないため、コストの最適化が可能。
OneLake によるデータの統合が可能
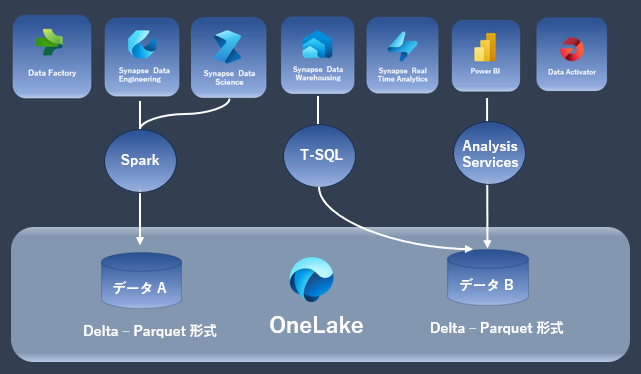
- Microsoft Fabric OneLake は、OSS Delta Lake をベースにしており、OneLake上に配置されたデータは Delta-Parquet (デルタ - パーケイ) 形式という単一の共有フォーマットで保存される。
- データが OneLake に保存されると、インポート/エクスポートをすることなく、Microsoft Fabric に統合されたワークロード、および、Azure Databricks、Azure Data Lake Storage Gen2 互換性アプリ (Azure HDInsight など) などからデータにアクセスすることが可能。

- ミラーリング機能により Azure Cosmos DB, Azure SQL Database, Mongo DB, Snowflake から ほぼリアルタイムで OneLake にデータを Dalta – Parquet 形式でデータ同期させることが可能。
※ 特に Snowflake がミラーリングのサポート対象になっている点が特徴的だと思います。 - ミラーリングされた各データは同一データフォーマット (Dalta – Parquet 形式) で保存されるため、OneLake上にある既存のデータとを簡易に結合して分析、視覚化させることが可能。
※ 異なるデータソースのデータを分析のために簡易にデータ結合を伴うデータ分析が実施できるのは嬉しい点だと思います。 - データ サイエンティスト, データ アナリストなどがほぼリアルタイムのデータを利用した分析が可能。
- 既存のデータを簡易に活用することが可能。
OneLake ショートカット機能によるデータアクセスが可能
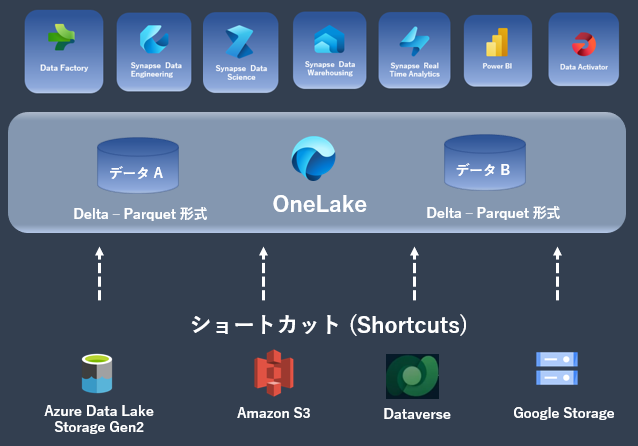
- OneLake ショートカット機能を利用することで、実データを OneLake にインポートする必要なく、Azure Data Lake Storage Gen2, Amazon S3, Dataverse, Google Storage に配置されたデータ(CSV, Parquet など) に直接アクセスすることが可能。
※ Google Storage へのショートカットについては、現時点 (2024年3月時点) でプレビュー機能。
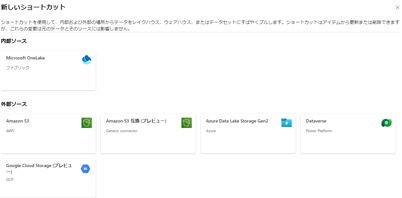
- 既存のデータを簡易に活用することが可能。
まとめ
今回は、「Microsoft Fabric」を利用するメリット (前半) について、まとめてみました。
メリット (前半) だけでも、データのサイロ化を防ぎ、効率的なデータ分析、AI分析を実施するために Microsoft Fabric を利用するメリットがあると感じられた方はおられるのではないかと思います。
次回は、「Microsoft Fabric」を利用するメリット (後編) で更なる Microsoft Fabric を利用するメリットについてまとめてみようと思います。
【第4回】基本から始める Microsoft Fabric【メリット 後半】へ
※ 2024年3月時点