Azure 分析基盤サービスとして以下のような様々なサービスが存在します。
- Azure Databricks
- Microsoft Fabric
- Azure Synapse Analytics
- HDInsight
- Azure Stream Analytics
- Azure Data Lake Analytics
今回は、その中の一つである「Azure Databricks」について、自分の整理も兼ねてまとめてみようと思います。
Azure Databricks とは
Databricks は データの取り込み (ETL)、分析、AI (生成AI)、機械学習 (Machine Learning)、BI (Business Intelligence) 、データ ガバナンス などの機能が統合された分析基盤サービス (レイクハウス プラットホーム) になります。
そして、Azure Databricks は、Azure 基盤に最適化され、Azure サービスと簡易に連携可能な フルマネージドの Databricks サービスとなります。
Azure Databricks の特徴
- データ分析に必要となる機能 (ETL、AI、DWH、ML、BI、データ ガバナンス など)が一つの共通プラットホームに統合され、構造化、半構造化、非構造化、ストリーミング データの分析が可能
- OSS (Apache Spark, DELTA LAKE, Koalas, Redash など) 製品を SaaS としてラッピングすることで簡易に利用することが可能
※ Apache Spark については パフォーマンス チューニング が施されている。 - データ エンジニア、データ アナリスト、データ サイエンティストなどの異なる役割をもったチーム間で共同で作業が可能
Azure Databricks のアーキテクチャ
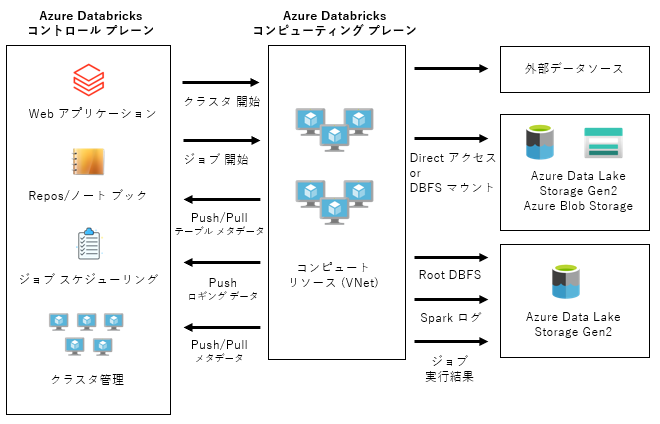
参考URL : Azure Databricks アーキテクチャの概要 - Azure Databricks | Microsoft Learn
Azure Databricks コントロール プレーン
Azure Databricks サービス Web アプリケーション、ノートブック、ジョブスケジュールのメタデータ、クラスタのメタデータを保持している。
Azure Databricks コンピューティング プレーン
Apache Spark、ノートブック、ジョブなどを実行するためのコンピューティング リソース、ストレージを保持している。
※ 但し、Databricks SQL サーバーレス などについては、Azure Databricks コントロール プレーン側のコンピューティング リソースが使用されるようです。
Azure Databricks ワークスペースを独自のAzure 仮想ネットワークにデプロイすると、該当のAzure 仮想ネットワーク内に Azure Databricks ワークスペースがデプロイされます。
まとめ
今回は、「Azure Databricks」の簡易的なアーキテクチャについてまとめてみました。
「Azure Databricks」では、パフォーマンス チューニングされた Apache Spark を利用できたり、データ分析に必要となる機能 (ETL、AI、DWH、ML、BI、データ ガバナンス など)が一つの共通プラットホームに統合され、構造化、半構造化、非構造化、ストリーミング データの分析が可能なサービスとなっています。
また、OSS がベースになっているため、移植性 (ポータビリティ) という意味でも優位性があり、更にAzure 関連サービスとの柔軟な連携が可能となっている点に優位性があるのではないかと思います。
参考URL
※ 2024年1月時点