Azure Synapse Analytics 専用 SQL プール (旧 SQL DW) は、SQL Server をベースにした Azure で使用可能なマネージドのデータウェアハウス サービスであり、PolyBase、Azure Data Factory、BCP などを使用し、ビック データをデータベースに取り込んだ後、分散クエリ エンジンの機能により、ペタバイト規模のデータを高速に分析することが可能なサービスです。
今回は、Azure Synapse Analytics 専用 SQL プール (旧 SQL DW) のアーキテクチャについて、まとめてみようと思います。
Azure Synapse Analytics 専用 SQL プール アーキテクチャ

基本構成
Azure Synapse Analytics 専用 SQL プールは、「コントロール ノード」、「コンピュート ノード」、「ディストリビューション」、「データ移動サービス (DMS)」、「Azure ストレージ」などのノード、コンポーネントによって構成されています。
コントロール ノード (制御ノード)
クライアント (アプリケーション) との接続を管理するノード。分散クエリ エンジンも動作しており、クライアントから受信したクエリを並列クエリに変換し、各コンピュート ノード (計算ノード) で動作するディストリビューションへの展開、同時実行スロット制御も本ノードで行われる。
コンピュート ノード (計算ノード)
計算能力を提供するノード。クエリを実行するディストリビューションを保持している。
コンピュート ノード数は、専用 SQL プールのサービスレベル (Data Warehouse ユニット (DWU)) により、1 から 60 の範囲で設定される。
例えば、サービス レベル 「DW100c」の場合、コンピュート ノード数は 「1」、「DW2000c」の場合、コンピュート ノード数は「4」に設定される。
その他のサービス レベルについては、以下の URL を参照。
ディストリビューション
並列クエリ実行する基本的な単位であり、各 Azure Synapse Analytics 専用 SQL プール毎に「60」存在し、各コンピュート ノード上に分散されて動作している。
例えば、サービス レベル 「DW100c」の場合、コンピュート ノード数は 「1」であるため、1つのコンピュート ノードに 60個のディストリビューションが配置され、「DW2000c」の場合、コンピュート ノード数は「4」であるため、各コンピュート ノードには、15個(60/コンピュート ノード数) のディストリビューションが配置される。

データ移動サービス (DMS)
コンピュート ノード間のデータ移動のためのデータ転送テクノロジであり、各コンピュート ノードでクエリ処理を完結できず、他のコンピュート ノードからデータを取得する必要がある場合などに使用される。
Azure ストレージ
インポートしたデータが保存されたデータベース物理ファイル (.mdf) が保存されている。データをどのように分散させるかについては、テーブル作成時に「DISTRIBUTION」句で指定することが可能であり、「HASH (ハッシュ)」、「ROUND_ROBIN (ラウンドロビン)」、「REPLICATE (レプリケート)」から選択可能となっている。
例:ハッシュ分散テーブルを作成する場合
| CREATE TABLE dspTable ( id int NOT NULL, name nvarchar(50) ) WITH ( DISTRIBUTION = HASH (id), CLUSTERED COLUMNSTORE INDEX ); |
クエリ実行までの流れ
1) クライアント (アプリケーション) からコントロール ノードへの接続が確立される。
2) クライアントからのクエリ要求をコントロール ノードが受領する。
3) コントロール ノード上の分散クエリ エンジンで構文解析が行われ、並列クエリに変換し、各コンピュート ノード (計算ノード) で動作するディストリビューションへ展開する。
4) コンピュート ノード上のディストリビューションで展開されたクエリを実行する。
4-1) 各コンピュート ノードのみでクエリを完結できる場合
-> 展開されたクエリがそのまま実行される。
4-2) 各コンピュート ノードのみでクエリを完結できない場合
-> データ移動サービス (DMS) により、最もデータ移動が少なくなるコンピュート ノード上にデータを集約する動作が行われ、データの集約が完了後、クエリが実行される。
5) 各コンピュート ノードの実行結果がコントロール ノードに返され、コントロール ノードからクライアントに対して結果セットが返される。
[パターン例]
1) 各コンピュートノードでクエリを完結できる場合

2) 各コンピュートノードの結果セットを集計する必要がある場合
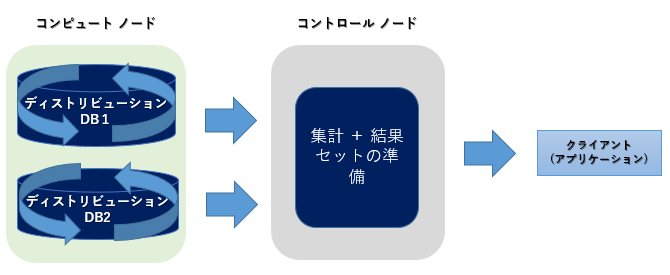
3) 各コンピュートノードでクエリを完結できず、他のコンピュートノード上のデータが必要な場合

まとめ
今回は、Azure Synapse Analytics 専用 SQL pool (旧 SQL DW) のアーキテクチャについて、まとめてみました。
次回以降で「テーブルの種類」 、「リソース クラス」、「Azure Synapse Analytics 専用 SQL poolのベストプラクティス」について、まとめてみようと思います。