オンプレミス環境で動作している SQL Server AlwaysOn 可用性グループ環境をAzureへ移行することを検討する際、マネージドのサービスである Azure SQL Database、Azure SQL Managed Instance に移行することが可能となるかを検討することが多いかと思いますが、使用するアプリケーションがマネージドのデータベース サービスをサポートしていない (Active Directory Federation Services : ADFS などは、オンプレミス SQL Server のみをサポートなど) 場合、目標復旧時間 (RTO)、目標復旧時点 (RPO) などの非機能要件がマネージドのデータベースに定められている値よりも短く構成する必要がある場合など、Azure仮想マシン上に SQL Server AlwaysOn可用性グループの構築が必要になることがあると思います。
今回は、Azure仮想マシン上に高可用性(ゾーン冗長)を考慮したSQL Server AlwaysOn可用性グループを構築するための勘所についてまとめてみようと思います。
【ゾーン冗長を考慮した構成例】

- 勘所ポイント
- ポイント1 : ゾーン冗長を考慮したAzure仮想マシンのデプロイ
- ポイント2 : WSFC のクォーラムをクラウド監視で構成
- ポイント3 : WSFC のハートビート間隔設定を30秒(30000 ミリ秒)以上に設定
- ポイント4 : SQL Server AlwaysOn 可用性グループ リソースの Lease Timeout および HealthCheckTimeout の値を30秒(30000 ミリ秒)以上に設定
- ポイント5 : SQL Server AlwaysOn 可用性リスナーに紐づけるロードバランサー(ILB)のSKUをStandardおよびゾーン冗長に設定
- ポイント6 : Azure上の高可用性のサービス(データベースなど)に接続するアプリケーションでは、リトライ処理を実装し、エラーハンドリングできる状態にする。
- ポイント7 : サーキット ブレーカーの実装を検討する。
- まとめ
勘所ポイント
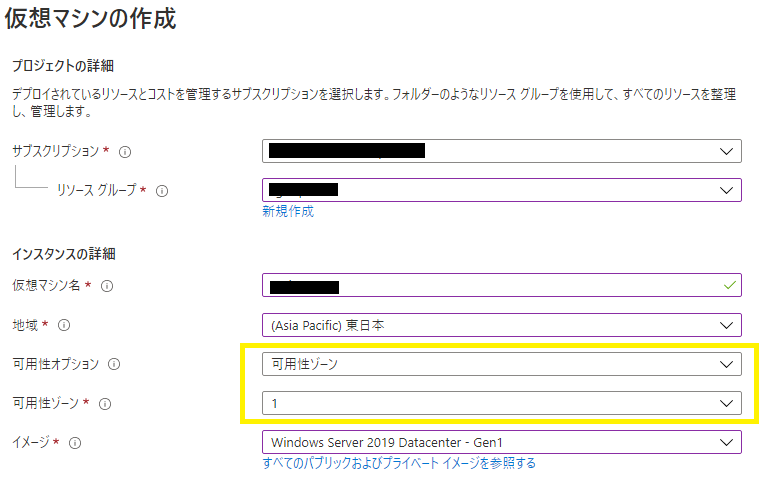
ポイント1 : ゾーン冗長を考慮したAzure仮想マシンのデプロイ
SQL Server AlwaysOn 可用性グループを構成する Windows Server および Active Directory を冗長化構成する Windows Server は、異なる可用性ゾーンにデプロイしたAzure仮想マシン上にインストールします。
[例]
SQL Server AlwaysOn 可用性グループ ノード1は ゾーン1、ノード2はゾーン2 に配置するなど。
ポイント2 : WSFC のクォーラムをクラウド監視で構成
Windows Server 2016/2019 では、Windows Server Failover Clustering (WSFC)のクォーラムにOS標準機能として選択可能な クラウド監視 を選択します。
参考情報
[補足]
クラウド監視に指定するAzure Storageをデプロイ時、ゾーン冗長ストレージ (ZRS) を指定します。
ポイント3 : WSFC のハートビート間隔設定を30秒(30000 ミリ秒)以上に設定
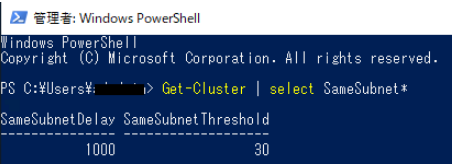
WSFC のハートビート間隔設定で SameSubnetDelay (単位:ミリ秒) * SameSubnetThreshold (単位:回数) の値が、30秒 (30000 ミリ秒) 以上になるようにパラメータ値を変更します。
[例]
SameSubnetDelay = 1000、SameSubnetThreshold = 30 などに変更。
[補足]
Azure 仮想マシンでは、メンテナンスによる再起動を可能な限り発生させないよう、ライブ移行("メモリ保護" 更新) テクノロジーが使用されています。
本テクノロジーを実現するにあたり、Azure仮想マシンで30秒以内のフリーズ状態が発生します。
WSFCのハートビート間隔を30秒より短い時間に設定すると、30秒以内のフリーズ状態時に不要なフェールオーバーが発生する可能性があるため、本間隔を 30秒以上に設定することが推奨されています。
なお、Azure 仮想マシン上で Windows Server 2019 を使用した WSFCを構成する場合、WSFCのハートビート間隔設定が、「SameSubnetDelay = 1000、SameSubnetThreshold = 30」になっています。
参考情報
ポイント4 : SQL Server AlwaysOn 可用性グループ リソースの Lease Timeout および HealthCheckTimeout の値を30秒(30000 ミリ秒)以上に設定
ポイント3と同様に、Azure仮想マシンでは 30秒以内のフリーズ状態が発生するため、不要なフェールオーバーの発生を防ぐため、SQL Server AlwaysOn 可用性グループ リソースの Lease Timeout および HealthCheckTimeout の値を30秒(30000 ミリ秒)以上に設定します。
1) Lease Timeout 値を 30秒 (30000ミリ秒) 以上に設定する。(既定値: 20秒 : 20000ミリ秒)
Lease Timeout 値を設定する場合、Lease Timeout値 * 1/2 の値が WSFCのハートビート間隔 (SameSubnetDelay (単位:ミリ秒) * SameSubnetThreshold (単位:回数) ) の値 よりも短くなるように設定する必要があります。
2) HealthCheckTimeout 値をLease Timeout 値に指定した値よりも長く設定する。(既定値: 30秒 : 30000ミリ秒)
HealthCheckTimeout 値は、Lease Timeout 値よりも長く設定する必要があるため、Lease Timeout 値を変更した場合は、HealthCheckTimeout 値も延ばします。
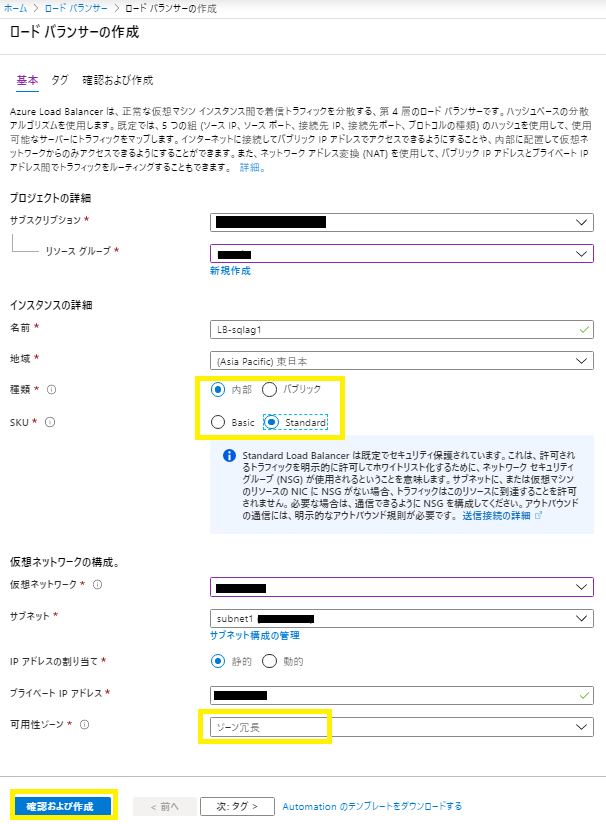
ポイント5 : SQL Server AlwaysOn 可用性リスナーに紐づけるロードバランサー(ILB)のSKUをStandardおよびゾーン冗長に設定
SQL Server AlwaysOn 可用性グループに接続するロードバランサーについても、 ロードバランサー(ILB) 作成時、種類:「内部」、SKU :「Standard」、可用性ゾーン : 「ゾーン冗長」を選択して作成します。
参考情報
ポイント6 : Azure上の高可用性のサービス(データベースなど)に接続するアプリケーションでは、リトライ処理を実装し、エラーハンドリングできる状態にする。
今回の構成に限った話ではありませんが、パブリッククラウドサービスのSLAは100%ではなく、高可用性を維持するために、内部的にフェールオーバーなどが実施されています。そのため、クラウドサービス(特にデータベースなど)へ接続するアプリケーションでは、フェールオーバーに伴い、実行中の処理が失敗したり、該当のサービスに接続できないなどの問題に対処するため、アプリケーション側でエラーをハンドリングし、リトライ処理を実装することが推奨されています。
Azure 仮想マシン上に構成した SQL Server AlwaysOn 可用性グループにおいても、何らかの問題が発生した場合、自動フェールオーバーが発生する可能性があるため、アプリケーション側でリトライ処理の実装を実施することが同様に推奨されます。
※ リトライ処理を実装する場合、リトライ間隔、リトライ回数も重要な要素となり、リトライ間隔については、数秒 (5秒など) 以上に設定することが推奨されています。
ポイント7 : サーキット ブレーカーの実装を検討する。
ポイント6でリトライ処理の実装を推奨するという内容を記載しましたが、即座に解決しない問題が発生した場合、複数のプロセスで同時に大量のリトライ処理が実行されることで、 急激なトラフィックの増加に伴い、障害範囲が拡大する可能性もあります。
そのため、リトライ処理を何回か実行したとしても現象が解消しない場合においては、失敗を処理するロジックを追加するといった実装を実施することが推奨されています。
参考情報
まとめ
今回は、Azure仮想マシン上に高可用性(ゾーン冗長)を考慮したSQL Server AlwaysOn可用性グループを構築するための設計の勘所についてまとめてみました。今後、新しいサービスや新機能が追加された場合、内容のブラッシュアップをしていこうと思います。
※ 本ブログの情報は、2022年3月 時点のものなります。